在上節中,我們介紹了監督學習在股市裡的應用,在本節中,我們將結合無監督學習和模型優化技術。首先,我們將探討如何應用聚類算法(如K-Means)來識別市場模式,以及如何使用主成分分析(PCA)進行數據降維。接著,我們將深入了解模型優化的方法,包括超參數調整和交叉驗證,以防止過擬合並提高模型的泛化能力。今日 Colab
無監督學習是一種機器學習方法,利用未標記的數據來發現數據中的內在結構或模式。與監督式學習不同,無監督學習不需要目標變量(標籤),主要應用於:
K-Means是一種常用的聚類算法,目的是將數據分成 ( K ) 個聚類,使得同一聚類內的數據點彼此盡可能接近,而不同聚類之間的數據點盡可能遠離。
K。K 個初始質心。import pandas as pd
import numpy as np
import yfinance as yf
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
import seaborn as sns
# 獲取多支股票的數據
tickers = ['AAPL', 'MSFT', 'GOOGL', 'AMZN', 'META', 'TSLA', 'NVDA', 'JPM', 'V', 'JNJ']
data = yf.download(tickers, start='2020-01-01', end='2021-01-01')['Adj Close']
# 計算每日收益率
returns = data.pct_change().dropna()
# 計算平均收益率和波動率
mean_returns = returns.mean() * 252
volatility = returns.std() * np.sqrt(252)
# 構建特徵數據集,添加股票代碼
features = pd.DataFrame({'Ticker': tickers, 'Mean Returns': mean_returns.values, 'Volatility': volatility.values})
# K-Means 聚類
k = 3 # 假設分為 3 個聚類
kmeans = KMeans(n_clusters=k, random_state=0)
kmeans.fit(features[['Mean Returns', 'Volatility']])
labels = kmeans.labels_
# 添加聚類標籤
features['Cluster'] = labels
# 可視化聚類結果並標註股票代碼
plt.figure(figsize=(12,8))
scatter = sns.scatterplot(x='Volatility', y='Mean Returns', data=features, hue='Cluster', style='Cluster', s=100, palette='Set1')
# 調整圖例位置
plt.legend(bbox_to_anchor=(1.05, 1), loc=2, borderaxespad=0.)
# 添加股票代碼標籤
for i in range(features.shape[0]):
plt.text(x=features['Volatility'][i]+0.007, y=features['Mean Returns'][i]+0.007,
s=features['Ticker'][i],
fontdict=dict(color='black', size=10),
bbox=dict(facecolor='yellow', alpha=0.5, edgecolor='black'))
plt.title('股票聚類結果')
plt.xlabel('波動率')
plt.ylabel('平均收益率')
plt.show()
可以看到依照我們設定的各個股票的分類結果: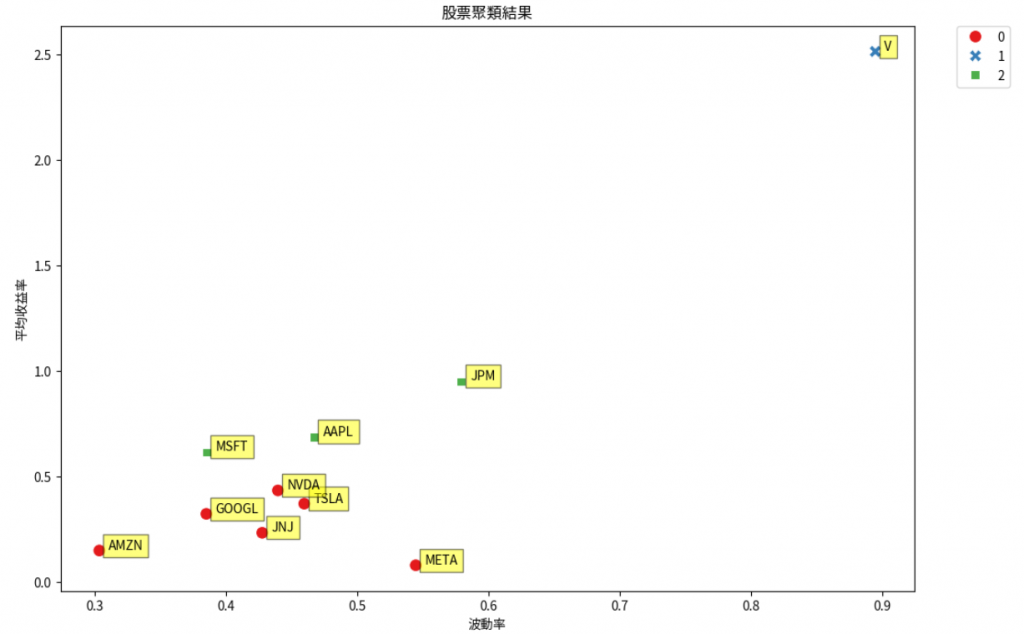
解釋:
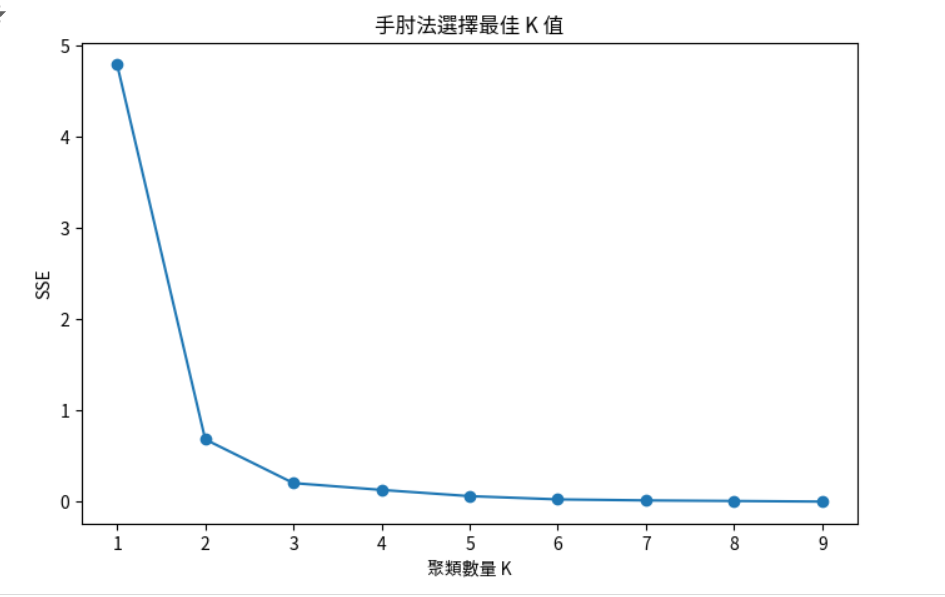
K 個聚類。K 值變化的圖,選擇拐點處的 K 值。sse = []
k_range = range(1, 10)
for k in k_range:
kmeans = KMeans(n_clusters=k, random_state=0)
kmeans.fit(features[['Mean Returns', 'Volatility']])
sse.append(kmeans.inertia_)
plt.figure(figsize=(8,5))
plt.plot(k_range, sse, marker='o')
plt.xlabel('聚類數量 K')
plt.ylabel('SSE')
plt.title('手肘法選擇最佳 K 值')
plt.show()
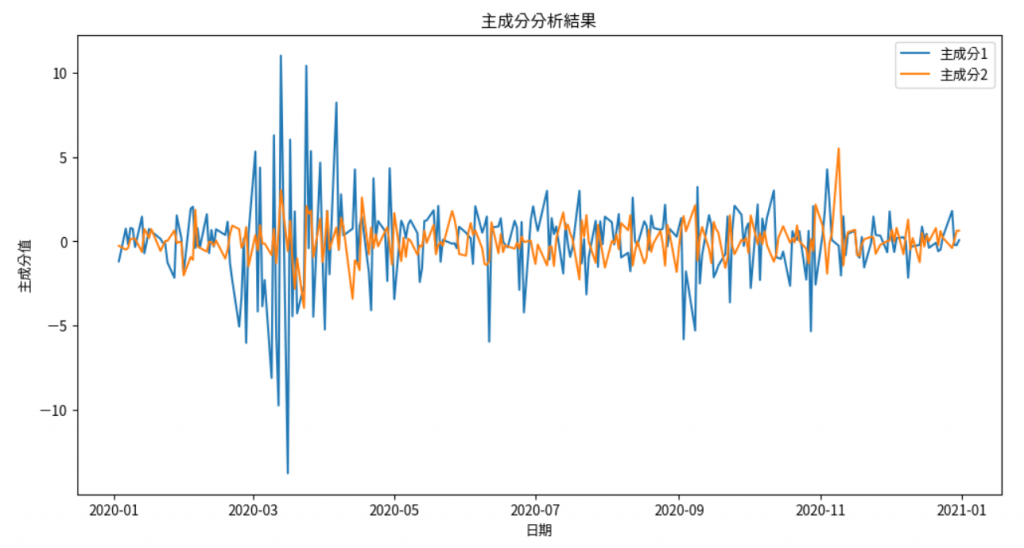
主成分分析(PCA)是一種降維技術,通過將高維數據投影到較低維的空間,提取數據中最重要的變異方向,同時保留主要信息。
# 使用前面獲取的 returns 數據
X = returns
# 標準化
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
from sklearn.decomposition import PCA
# 設置要保留的主成分數量
pca = PCA(n_components=2)
principal_components = pca.fit_transform(X_scaled)
# 解釋方差比例
explained_variance = pca.explained_variance_ratio_
print('解釋方差比例:', explained_variance)
# 將主成分轉換為DataFrame
pca_df = pd.DataFrame(data=principal_components, columns=['PC1', 'PC2'])

# 將日期加入DataFrame
pca_df['Date'] = returns.index
pca_df.set_index('Date', inplace=True)
# 繪製主成分隨時間的走勢
plt.figure(figsize=(12,6))
plt.plot(pca_df.index, pca_df['PC1'], label='主成分1')
plt.plot(pca_df.index, pca_df['PC2'], label='主成分2')
plt.title('主成分分析結果')
plt.xlabel('日期')
plt.ylabel('主成分值')
plt.legend()
plt.show()
import pandas as pd
import numpy as np
import yfinance as yf
from sklearn.model_selection import GridSearchCV, TimeSeriesSplit
from sklearn.svm import SVC
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import accuracy_score, classification_report
# 1. 獲取股票數據
data = yf.download('AAPL', start='2015-01-01', end='2021-01-01')
# 2. 特徵工程
data['Returns'] = data['Adj Close'].pct_change()
data['SMA'] = data['Adj Close'].rolling(window=20).mean()
data['Volatility'] = data['Returns'].rolling(window=20).std()
# 安裝並導入 ta 庫以計算 RSI
!pip install ta
import ta
# 計算 RSI
data['RSI'] = ta.momentum.RSIIndicator(close=data['Adj Close'], window=14).rsi()
# 移除缺失值
data.dropna(inplace=True)
# 3. 構建特徵和標籤
# 標籤:未來一天的價格漲跌
data['Target'] = np.where(data['Returns'].shift(-1) > 0, 1, 0)
data.dropna(inplace=True)
features = ['SMA', 'Volatility', 'RSI']
X = data[features]
y = data['Target']
# 4. 分割訓練集和測試集
# 保持時間序列順序,防止未來數據洩漏
split_date = '2020-01-01'
X_train = X[X.index < split_date]
X_test = X[X.index >= split_date]
y_train = y[y.index < split_date]
y_test = y[y.index >= split_date]
# 5. 標準化
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# 6. 定義參數網格
param_grid = {
'C': [0.1, 1, 10],
'gamma': ['scale', 'auto'],
'kernel': ['rbf', 'linear']
}
# 7. 建立模型
model = SVC()
# 8. 使用 TimeSeriesSplit 進行時間序列交叉驗證
tscv = TimeSeriesSplit(n_splits=5)
# 使用 GridSearchCV
grid_search = GridSearchCV(estimator=model, param_grid=param_grid, cv=tscv, scoring='accuracy')
grid_search.fit(X_train_scaled, y_train)
# 9. 最佳參數和模型
print('最佳參數:', grid_search.best_params_)
print('最佳交叉驗證得分:', grid_search.best_score_)
# 10. 使用最佳模型進行預測
best_model = grid_search.best_estimator_
y_pred = best_model.predict(X_test_scaled)
# 11. 評估模型
accuracy = accuracy_score(y_test, y_pred)
print(f'測試集準確率:{accuracy:.2%}')
print('分類報告:\n', classification_report(y_test, y_pred))
可得: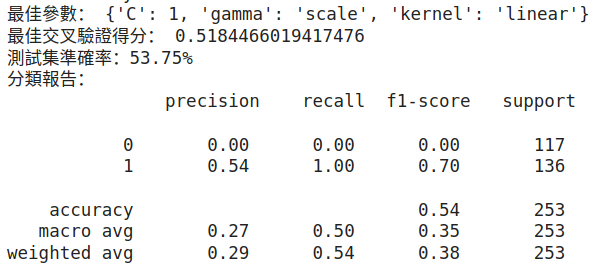
交叉驗證是一種評估模型性能的技術,通過將數據集劃分為多個子集,反覆訓練和測試模型,以獲得更穩定的評估結果。
步驟:
K 個子集。實現
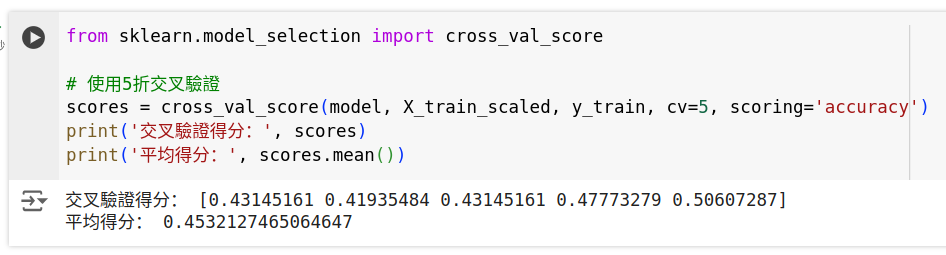
from sklearn.model_selection import cross_val_score
# 使用5折交叉驗證
scores = cross_val_score(model, X_train_scaled, y_train, cv=5, scoring='accuracy')
print('交叉驗證得分:', scores)
print('平均得分:', scores.mean())
from sklearn.linear_model import Ridge
# 使用Ridge回歸
model_ridge = Ridge(alpha=1.0)
model_ridge.fit(X_train_scaled, y_train)
from sklearn.tree import DecisionTreeClassifier
# 限制樹的最大深度
model_tree = DecisionTreeClassifier(max_depth=5)
model_tree.fit(X_train_scaled, y_train)
在本節中,我們:
在接下來的學習中,我們將進一步探討時間序列預測和深度學習等進階主題,提升模型的預測能力。
作業:
K 值。透過實踐,您將更深入地理解無監督學習和模型優化技術在金融機器學習中的重要性,為構建更精確和穩健的模型奠定基礎。
提示:
注意:
random_state以保證結果的可重現性。

 iThome鐵人賽
iThome鐵人賽